Building a Recommendation Engine using Spark and Hadoop
The project leverages collaborative filtering techniques to generate personalized recommendations, with a focus on scalability and efficiency in handling large datasets

Technological Stack
Implemented the system using Scala for programming, Spark for distributed data processing, and Hadoop HDFS for data storage. This combination ensures high performance and the ability to manage vast amounts of data.

Collaborative Filtering with ALS
Employed Spark's ALS (Alternating Least Squares) algorithm to perform collaborative filtering.
This technique effectively predicts user preferences based on historical interactions, enhancing the accuracy of recommendations.

Data Handling and Preparation
Collected data from the MovieLens dataset, consisting of 20 million ratings, 138,000 movies, and 270,000 users.
The dataset was stored in Hadoop HDFS for efficient handling. Data preprocessing involved cleaning the dataset by removing duplicates, filling missing values, and filtering irrelevant columns.
The cleaned data was transformed into a user-item matrix, which was then partitioned and distributed across the Spark cluster for parallel processing, ensuring efficient model training and scalability.
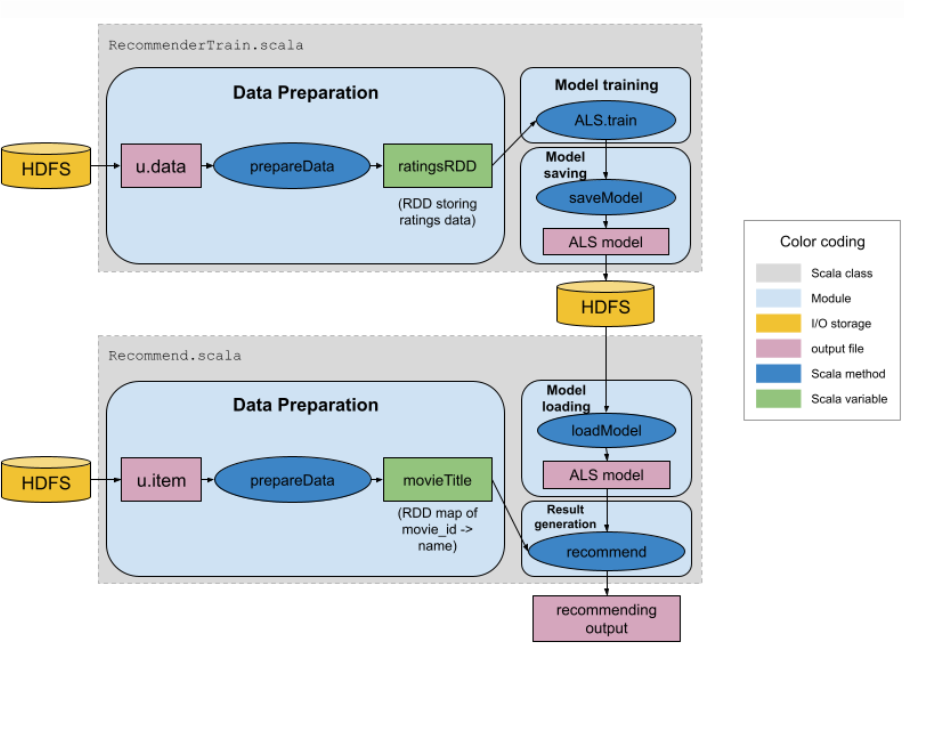
Model Building and Evaluation
The recommendation model was built using Spark's ALS algorithm, a collaborative filtering technique that factorizes the user-item matrix to predict ratings.
Hyperparameters were optimized through cross-validation, with performance assessed using RMSE and MAE metrics.
The model, once trained, was saved in HDFS and evaluated through holdout validation, demonstrating accuracy with low RMSE and MAE values.
Recommendations were generated for users by leveraging the trained model, offering personalized movie suggestions based on predicted ratings.

Conclusion and Future Work
Big data tools like Hadoop and Spark were instrumental in developing a recommendation model using collaborative filtering.
The ALS algorithm in Spark's MLlib library provided accurate recommendations. Real-time recommendations were achieved through Spark's streaming API and Flask integration.
Future enhancements include user clustering, social media integration, e-commerce integration, and exploring hybrid recommendation systems for improved accuracy.